前回までのおさらい
前回の記事 では、Web 検索エージェントの Reasoning Effort の変更とプロンプトの変更によって検索結果に基づいた回答をする確率を上げられることがわかった。
今回の記事では、URL を受け取ってページの内容を Markdown で返すツールを実装する。
HTML を Markdown に変換するには
HTML を Makrdown に変換する方法はいくつかあるだろう。結論だけ先に書くと、今回は Jina AI が公開している ReaderLM-v2 をローカル環境で実行し、
HTML を Markdown に変換する方法を採用する。
Jina AI は AI を使った検索機能を API を提供している。検索自体を丸投げすることもできるし、Web ページや PDF を Markdown に変換するような機能もある。技術的には LLM によるドキュメント変換、埋め込み(Embedding)、再ランク付け(Reranker)、検索(Retrival)に特化してサービスを展開しているということになるのだろうか。無料モデルを多数公開しており、今回使う ReaderLM-v2 もそのうちの一つだ。埋め込みや再ランク付けのためのモデルも公開しているようなので、Web 検索 AI エージェントの開発の一区切りついたら触ってみたい。
HTML から Mawrkdown への変換は ReaderLM-v2 を使うとして、HTML の取得は直接 URL を叩いて取得するだけでもよいが、
JavaScript が動かないとコンテンツが取得できないようなページもデータソースとして使っていきたいので Playwright を使う。取得した HTML をそのまま ReaderLM-v2 の入力として与えると HTML が巨大すぎて扱えるトークン数の上限に到達したり、変換にかかる時間が大幅に増加する。そのため、Hugging Face の README.md にも書かれているように前処理が必要になる。正規表現による置換でも十分だとは思えるが DOM 操作は前回と同様 Cheerio を使う。
つまり、今回の記事では以下に触れる。
さぁ、実装を進めよう。
Playwright の導入
最初に Playwright をセットアップする。 Playwight は次のコマンドでインストールできる。
次に Playwright が使うためのブラウザをダウンロードする。
npm init playwright@latest を実行したとき、Install Playwright browsers を yes で回答した場合は次のコマンドは不要だ。
最後にこれらのコマンドで tests/ ディレクトリが作成されるが今回は不要なので削除しておこう。
HTML から Markdown へ変換する Agent
今回は Web ページの内容を取得し、HTML を Markdown へ変換する処理の一部として ReaderLM-v2 を使う。
mastra では Agent を定義するとツールの中で呼び出せるようになるため、最初に ReaderLM-v2 をモデルに指定した Agent を実装しよう。
具体的なコードは次のようになる。
instructions には何も与えない。
README.md に書かれた使い方でも会話は user から始まっているのでシステムプロンプトを与えないのが正しい使い方だと思う。
このコードの中で HTMLCleaner はこれまでのシリーズでも出ていない部分になる。
mastra の Agent 機能の一つとして、メッセージ(会話)に対して事前処理、事後処理を設定できる。ここでは inputProcessors に入力として与えられる HTML からサイズを小さくするために不要な情報を除く処理を渡している。
HTMLCleaner は mastra の Processor を実装するクラスとして実現される。ここでは、具体的な実装として次のようなコードを書いた。
コンストラクタの引数でいくつかオプションとして動作を変えられるようにしているが、オプションなしのメインのロジックについて説明する。やっていることは次の通り。
- ユーザーが入力したメッセージのみを対象とする
- コンテンツが
textのメッセージのみを対象とする - Cheerio でコンテンツの内容(HTML)を読み込む
head,link,script,style,noscript,header,footer,nav,svg,templateタグを削除href,src,id以外のすべてのタグ属性を削除srcにdata:から始まる値が設定されている場合は#で置換- 不要な情報を削除した HTML でメッセージを置き換え
これにより、HTML のサイズを小さくなり ReaderLM-V2 で Markdown に変換する速度が大幅に改善する。
最後に忘れずに実装した Agent が mastra で認識されるようにコードを修正しよう。
Markdown Agent の動作を確認する
mastra を起動して Agents に Markdown Agent が追加されているはずなので選択してチャット UI を開く。
入力として HTML を与えると画像のように Markdown を出力し始める。
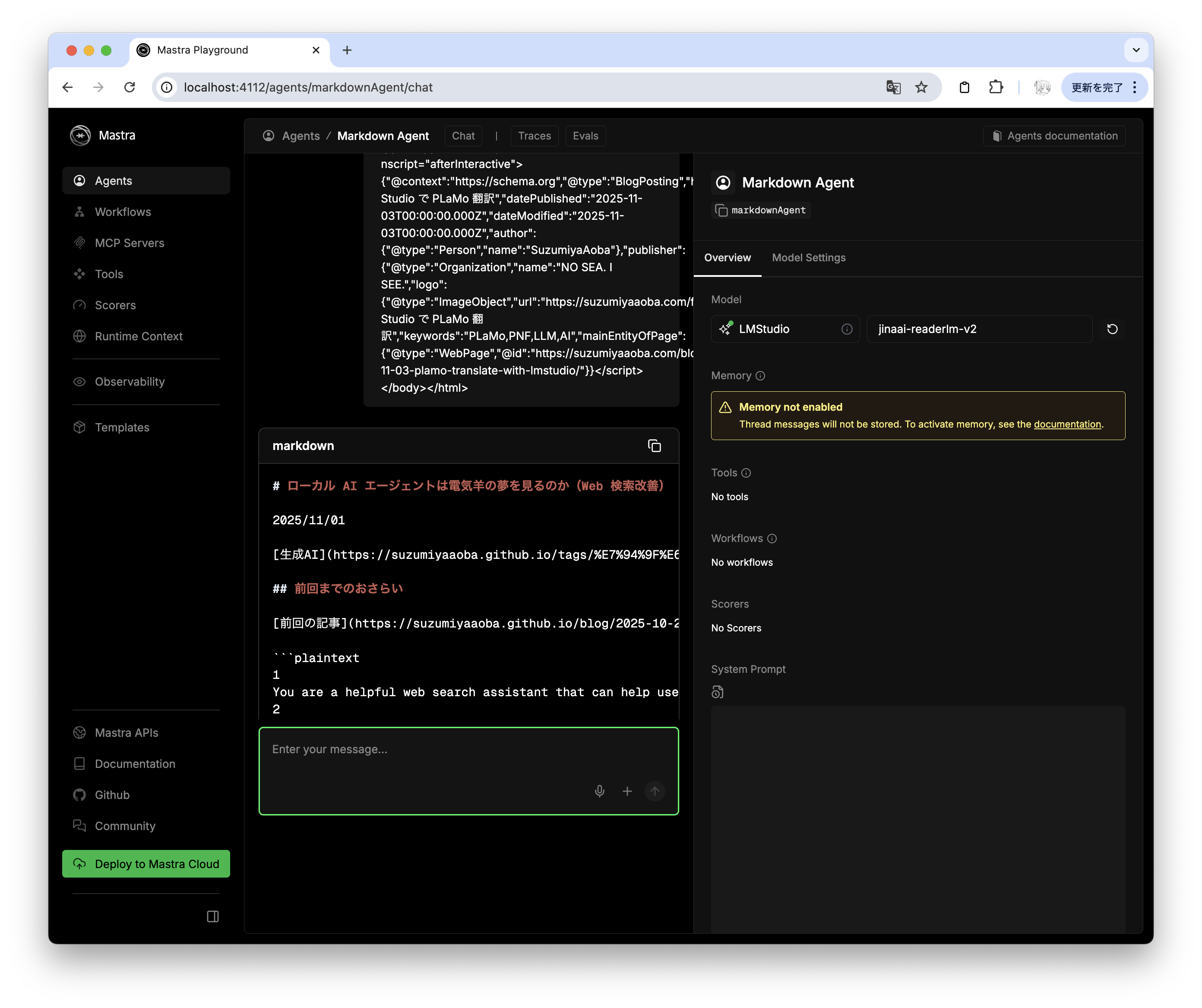
出力が ```markdown で囲まれるように出力されてしまっているが気になるようであれば outputProcessors で HTMLCleaner のように
LLM の出力から ```markdown を消すような事後処理を書いてあげればよい。
r.jina.ai
実はこんな面倒なことをしなくても Web ページを Markdown に変換する方法を Jina AI が提供してくれている。
Markdown に変換したいページの URL の先頭に r.jina.ai を付けるだけでいい。例えば Jina AI の Reader API について書かれた https://jina.ai/ja/reader/ を Markdown に変換するには、
https://r.jina.api/https://jina.ai/ja/reader/ のように https://r.jina.api/ を URL の前につける。
Web ブラウザでは https:// は省略できるので不要だ。
r.jina.ai を付けた URL にアクセスし、少しだけ待つと Markdown が表示されるはずだ。
API キーを必要としないこの方法に制限がないのか、IP アドレスや Cookie をベースとした利用制限がかかるのかは不明だ。しかし、ローカルで ReaderLM-V2 が動かせるスペックがないかったり、こちらの方が実行速度が早いようであればローカル環境で変換処理をするよりもいいかもしれない。
Web ページ取得ツール
HTML から Markdown へ変換する手段を手にしたので URL から HTML を取得する部分を実装しよう。これは、簡単で mastra のツールとして実装する。
エージェントに Web ページ取得ツールを追加
実装した webFetchTool を Web 検索エージェントに与える。これで検索だけではなく、取得した URL からウェブページの中身を LLM が認識できるようになったはずだ。
これでウェブページの内容まで確認して回答してくれるようになった…
ウェブページの内容を踏まえた回答
はずだった。これまでと同じように「今日の日本のニュースを教えて」と聞いてみる。そうするとどうだろう。
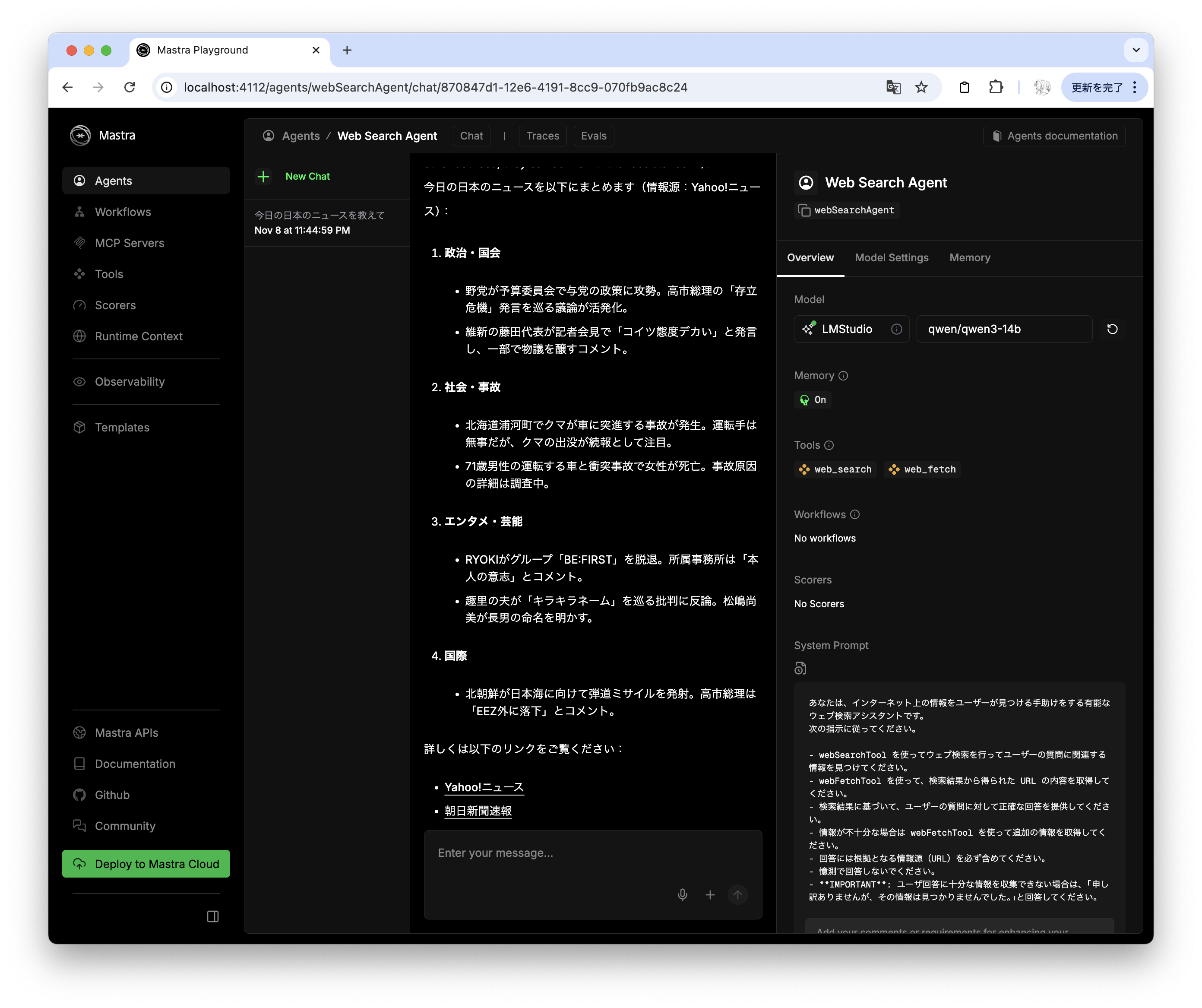
今日の日本のニュースを教えて
何も回答しれくれない。
その謎を解明するため、我々調査隊はアマゾンの奥地へ向かったーー。
ツール呼び出しが上手くいかない
何となくそんな気はしてましたよ。ツール使用回数が 5 回に到達すると回答が返ってこないことがあるなと思っていた。そこで ChatGPT のウェブ検索を使って調べたら同じことを言っている人が私以外にもいることがわかった。
- GPT-OSS 120B and 20B feel kind of… bad? : r/LocalLLaMA
- GPT-OSS not completing tool calls · Issue #12187 · ollama/ollama
- [Usage]: gpt-oss-120b tool calls · Issue #22337 · vllm-project/vllm
- Gpt-oss-120b ignoring tools - Forum - Groq Community
- Tool Calling GPT-OSS-20b and 120b - AI & Data Science / NVIDIA NIM - NVIDIA Developer Forums
困った。120B でも同様の問題が発生しているので 20b だと性能が不十分という理由ではないようだ。実際、gpt-oss ではなく Qwen を使うとツール呼び出しを使った後に回答が返ってくることが確認できる。
今後の方針
悲しいことに gpt-oss を単に使うだけでは上手くいきそうもないことがわかった。そのため、Web 検索エージェント実現のために他のモデルと組み合わせつつ、次のようなワークフローを構築してどこまで上手くいくのか試してみる。
- ユーザープロンプトの分析
- Web 検索プラン作成
- プランレビュー
- Web 検索
- Web ページ取得
- Web ページの要約
- 情報分析
- 再検索の必要性を判定
- 回答作成
簡単に思いつくワークフローとして先ずはこれを実装し、どの程度の回答が得られるのか見てみたい。また、各フェーズに対してハルシネーションがないか LLM 自身(複数のモデルを組み合わせ)に検証させる必要もあるだろう。
1 回のワークフローの実行に 1 時間以上かかるようになりそうな予感がしているが、それでもローカルで完結して回せるようになったら面白い。
最近話題の NVIDIA DGX Spark のようなものが広く普及するようになったら API 使用料を払って高性能モデルに任せるほどでもないことはローカルであるのが当たり前の未来が数年のうちに来るのだろうか。
