注意
2025/05/01 時点の情報を元に書かれた記事です。 LLM 関係の情報は日々変化しているため、最新情報は読者自身で確認してください。
はじめに
GW も残りわずかとなってしまった。今年はずっと LLM を触ってコーディングがどこまでできるのかを試しているだけで終わってしまったが、これまで思っていた以上に実用的な段階まで技術が進歩していることが確認できた。認識を改める必要がある。
X(旧 Twitter)上では「XXX がプロンプト入力しただけでできた!」とキャッキャしている人たちはよく見かけたが、正直なところ多くのプログラマにとって重要なのは既存コードに対してどのくらい実用的であるかだ。
文字通り 0 からコード生成するような場面というのは、多くの職業プログラマが遭遇するような場面ではない。ほとんどの人は、誰が書いたのかもわからない(git blame すればわかるけど)ようなコードが何をしているのかを理解し、案件ごとの要件を満たすような変更を加えていくのがソフトウェア開発の大半を占めているだろう。もちろんその過程で書かれるコードは新規コードかもしれないが、既存のコードとうまく協調する形で実装されなければならない。コード規模も数千行や数万行ではなく、数十万行規模で正しく動いてもらわねば困るのだ。
そう思っているので、LLM を使ったプログラミングの現在を知るためにこのブログの改善のために使ってみた感想を記す。
機能追加、改善
今回は Cursor を使ってこのブログの開発を行った。このブログ自体は去年の 7 月頃に作ったもので、最初に最低限の実装(記事一覧、詳細)をしてからほとんど手を加えてきていなかった。実装しないといけないと考えていた機能はいくつかあったが、どれもあっても無くても問題ではなかったのでいつまでも実装できずにいた。しかし、Cursor を使うことで GW 中にある程度の機能追加を行うことができた。
実装した機能は以下になる。
- タグ一覧
- タグが付いた記事一覧
- キーワード検索
- カラーテーマ
- 目次表示
- ヘッダーのデザイン改善
- パンくずリスト
どれも作りたいと思っていたし、どんなコードを書けばいいかは頭にはあるけど手を動かすに至っていなかったものだ。
まだページネーションや関連記事の表示といった、SSG で提供されているブログであれば備えている機能で実装できていないものがあるので、それも引き続き対応していこうと思う。
開発方法
Cursor には、主に以下の 3 つの機能がある。
- 賢い補完
- タブによる予測編集
- 自然言語による編集
詳細については Cursor 公式の機能を確認してほしい。
今回は自然言語による編集を主に活用して実装を進めた。生成されたコードに全く手を加えなかったわけではないが、1% にも満たないほどしか手を加えていなかったと思う。
Cursor のプラン
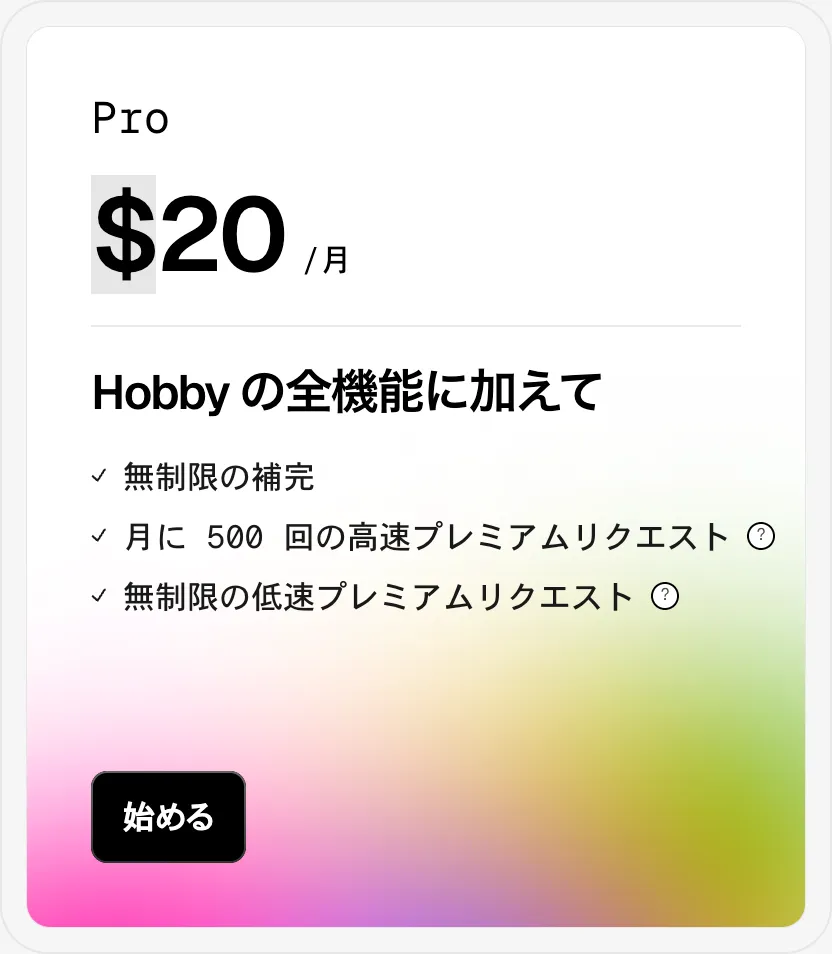
現時点では、
- 無制限の補完
- 月に 500 回の高速プレミアムリクエスト
- 無制限の低速プレミアムリクエスト
ができるプランとなっている。 500 回の高速プレミアムリクエストはあっという間になくなってしまうので、加入のメリットは「無制限の低速プレミアムリクエスト」だと思っている。
コード品質
コード品質は正直なところ良いとは言えない。 ここでコード品質は、解析性、変更性、安定性、試験性といった内部品質特性である保守性を支える性質のことを指している。生成されるコードは、既存実装やいわゆるベストプラクティスを無視するようなコードが出力されてしまうことが多い。それに加えてプロンプトを達成するためだけのコードが出力されることが多い。その結果として既存の機能を破壊してしまったり、賢いとは言えないコードが度々出力される。そのため、動くようなコードを生成させた後に自分で少しリファクタリングをするか、LLM 自身に改善すべき点がないか確認させなければならない。
このあたりは Rules を使っていないことが一因ではありそうなので改善していけるところではある。しかし、これまでの流れを見ていると半年もしないうちに claude-3.7-sonnet を凌駕するようなモデルが発表され、コードコンテキストをこれまで以上に正確に把握してコードを生成できるようになってくるだろう。
モデル
現在デフォルトで使えるモデルは以下のようになっている。
- claude-3.5-sonnet
- claude-3.7-sonnet
- gemini-2.5-pro-exp-03-25
- gemini-2.5-pro
- o3
- gpt-4.1
- gpt-4.0
- deepseek-r1
- deepseek-v3
もちろん、ユーザーが使用するモデルを追加することができるためこの限りではないが、私を含めて多くのユーザーはこの中から選択しているだろう。
コード規模
さて、現在このブログのコード規模はどのくらいだろうか?
tokei を使ってみると次のようになっていた。
1$ tokei src2━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━3Language Files Lines Code Comments Blanks4━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━5CSS 2 567 446 41 806MDX 22 5381 0 4108 12737Sass 3 499 407 10 828SVG 1 1064 1064 0 09TSX 93 6981 5963 363 65510TypeScript 25 1148 931 66 15111─────────────────────────────────────────────────────────────────────────────────12Markdown 3 252 0 174 7813|- Java 1 6 6 0 014(Total) 258 6 174 7815━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━16Total 149 15898 8817 4762 231917━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
記事コンテンツである Markdown ファイルも含んでしまっているため、そのままコード規模としてカウントするのは正しくないが、多少のノイズとなるようなファイルがある場合として目をつむれば 1.5 万行弱といったところだ。 Markdown ファイルを除くと概ね 1 万行くらいだろうか。
まだまだ少ないコード量だ。これくらいのコード量であれば、Cursor を使っていてコード規模の問題で正しく実装できない、という問題は発生しなかった。しかし、それがコード量の問題なのか、使っている言語、フレームワーク、ディレクトリ構造によるものなのかはわからない。そのため、今後は業務でこの手の類似サービスを利用し(Cursor は職場で使えないため)、よりコード規模が大きく、マイナーな技術スタックによって構築されたアプリケーションについて意図した通りのコード生成をさせるためのノウハウを蓄えていきたい。
メリット
さて、Cursor を使ってみて感じている最大のメリットはコードを生成させている間に他の作業を進められる点だろう。つまり、Cursor が提供しているような自然言語によって実装する機能は、現時点においては品質の高いコードを生成させるために使うというよりは、文字通りコパイロットにある程度の仕事を任せるような使い方に適していると思った。
現在もこの記事を書きつつブログの改善をさせている。高速リクエストを上限まで消費してしまった後でも低速で十分満足できる速度でレスポンスを得られているため、執筆の傍ら LLM が生成するコードを眺めて生成が完了したらフィードバックするということを繰り返している。
問題点
メリットもあれば問題点もある。
一つ目は、人なら一瞬で解決できる問題を永遠に解決できないことがあるという点だ。実際にこのブログにカラーテーマを追加するとき、Cursor の自然言語による実装ではいつまで経ってもサイトのカラーテーマに連動して Giscus のカラーテーマを変更することができなかった。
原因は単純で next/theme から useTheme を import すべきところを自身が実装した独自の useTheme を使ってしまい、サイトのカラーテーマは next/theme で管理されているが、Giscus のカラーテーマは独自の useTheme で管理している、といった状態に陥っていたためテーマが正しく反映されなかった。これは、人が少しコードを見れば簡単に気がつけるミスで、実際に行なった修正は import を直すだけの 1 行だった。この手の既存コード(LLM 自身が一時的に生成したコードを含む)を疑わず、それを使う形で無理に他のコードに変更を加えて与えられた指示やエラーを解決しようという挙動は頻繁に見られる。
この手の無限エラーループは Zenn、Qiita、ブログ、SNS で報告されているのを目にしてきたが、実際に体験すると人なら簡単に直せるようなミスをいつまでも解決できないというのは悲しい。というのも、人が書くのであれば 1, 2 時間かかるであろう実装が数分で返ってくることもあるわけで、上手くいくときと上手くいかないときの差が激しい。
二つ目は、無理矢理にでも指示された機能を実現しようとするという点だ。これはプロンプトや Rules が整備されていないことに起因するとは思うが、変更して欲しくないファイルにまで手を入れてありとあらゆる手段を使ってどうにか実装が動くように色々な変更を加える。その結果、大量の差分が発生するので git reset --hard などで元に戻してからプロンプトを考え直さないといけない。この辺をサポートするためにコンテキストにファイルを加えて制御することはできそうだが、もっとうまくやって欲しいというのは贅沢だろうか。
三つ目は、生成したコードの掃除をしないということだ。一発で上手く行けば問題ないが「ビルドが通るように」、「テストが成功するまで」というような指示を出すとそれが達成されるまで色々な実装方法を試し始める。そうして、最終的に上手く行くと実装の完了を知らせてくれるわけだが試行錯誤の過程で上手く行かなかったときの残骸をそのまま放置する。これが少し面倒なことになる。でき上がったコードから不要なものを手動で削除すればいいと言われればそれまでではあるが、試行錯誤するときに最初の方法が駄目だった場合に二つ目の方法を試すときに一つ目の方法を試したときのコードを利用しようとする。その結果、自分で書いたコードが原因で迷子になる。そんなことが何度も発生した。これも Rules を整備してプロンプトを工夫したら上手くできるようになるのかもしれないが、そのあたりは指示せずとも判断してもらえると嬉しい。
これからのプログラミング
今回、LLM を活用したプログラミングを経験してみて、これまでのプログラミングのやり方を変えていかないといけないところまで来ているように感じた。少し前までの GitHub Copilot のように賢い補完とチャットベースで質問したり、少しのファイル編集を行なったりというのとは全く異なる。特にアイディアとして全く新しいものではなく、既にこの世に存在するものを組み合わせてできるものの場合は、今までのやり方では新しいやり方についていけないのではないだろうか。
それをうまくやるためには、何か全く新しいことをしないといけないという風には思わなかった。これまでは個々のプログラマが自身の経験を元にそれとなく良しとして実装していたから上手くいっていた部分を真面目に取り組むことで、全体の生産性が上がっていくことになるだろう。
真面目に取り組む部分とは何か、それはテスト、設計、ドキュメンテーション、アーキテクチャの遵守、単一責任の原則を始めとするベストプラクティスの実践ではないだろうか。実践と言っているが、実際にそれらを生成するのは LLM であって人ではない。
コーディングの大部分が LLM に置き換わっていくため、これまでプログラマが培ってきたノウハウを LLM に理解させ、実践させることが大切になってくるだろう。 LLM は自然言語をある程度理解してくれるため、プログラマの経験に基づいて行っていた行為のドキュメント化が大切になる。
保守性を高めるためのプログラミングのノウハウの理解や実践は難しい。 DDD(Domain Driven Development)のような設計からコードレベルへ落とし込み、Clean Architecture のようなコードレベルのアーキテクチャ、TDD(Test Driven Development)といった実装の進め方、SOLID 原則の遵守、など。これらを見聞きしてもそのメリットを理解して実践していくのは一朝一夕ではいかない。そのため、これらを現場に取り入れていくにはチーム単位での教育が必要だったが、LLM が理解できるような形で一度ドキュメント化してしまえば、それだけでスケールさせることができ、保守性の高いプログラムを生成していけるようになるかもしれない。
プログラミング言語・フレームワーク
現在ではまだ LLM で生成されることに特化したプログラミング言語・フレームワークは登場していないが、近いうちに LLM ファーストを謳う言語の中からメジャーになる言語が出てくるだろう。
既存のものはあまり有力には思えない。
個人的には人間がするには手間もかかるし難しい形式的な証明、事前・事後条件を検証してくれて、コード内にコメントしてではなく LLM に対する指示が書けるような(必須)プログラミング言語が出てきて欲しい。
おわりに
今回は Cursor を使ってブログの改善を行い、LLM を活用したコーディングの現状について考察してみた。実際に使ってみた感想としては、「驚くほど使える」と「まだまだ発展途上」という二つの側面があると感じている。
LLM を活用したプログラミングは、コードの生成だけでなく、コードの理解や改善においても大きな可能性を秘めている。私のような個人開発者にとっては、「いつか実装したい」と思いながらも手をつけられずにいた機能を短期間で実装できるのは大きなメリットだ。
一方で、現時点ではまだ生成されるコードの品質には課題があるが、LLM をうまく使いこなし、より高度な抽象度で問題を考え、設計し、指示できるスキルが今後のプログラマには求められていくのではないだろうか。
